11、集合框架
1. 为什么使用集合框架
如果并不知道程序运行时会需要多少对象,或者需要更复杂的方式存储对象,那我们就可以使用 Java 的集合框架!
2. 集合框架包含的内容
Java 集合框架提供了一套性能优良,使用方便的接口和类,Java 集合框架位于
java.util包中
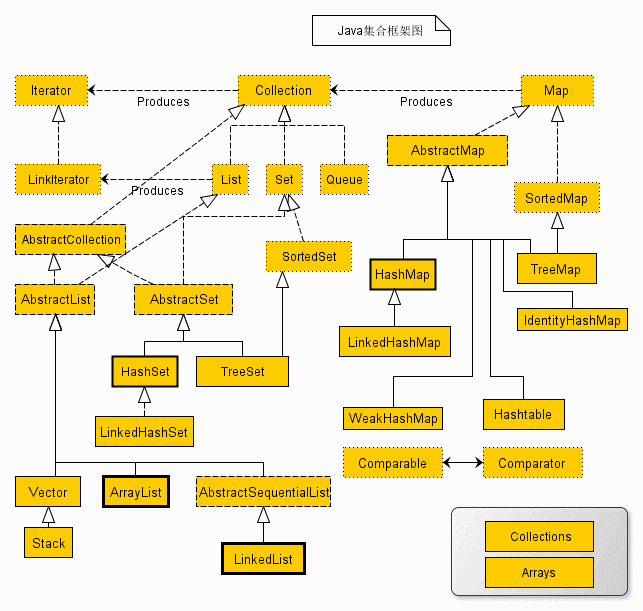
Java 集合框架主要包括两种类型的容器:
-
集合(Collection),存储一个元素集合
Collection 接口有 3 种子接口,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类
-
图(Map),存储键/值对映射
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
-
接口: 代表集合的抽象数据类型
例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象。
-
实现(类): 集合接口的具体实现
从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
-
算法: 实现集合接口的对象里的方法执行的一些有用的计算
例如:搜索和排序,这些算法实现了多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
集合框架体系如图所示:
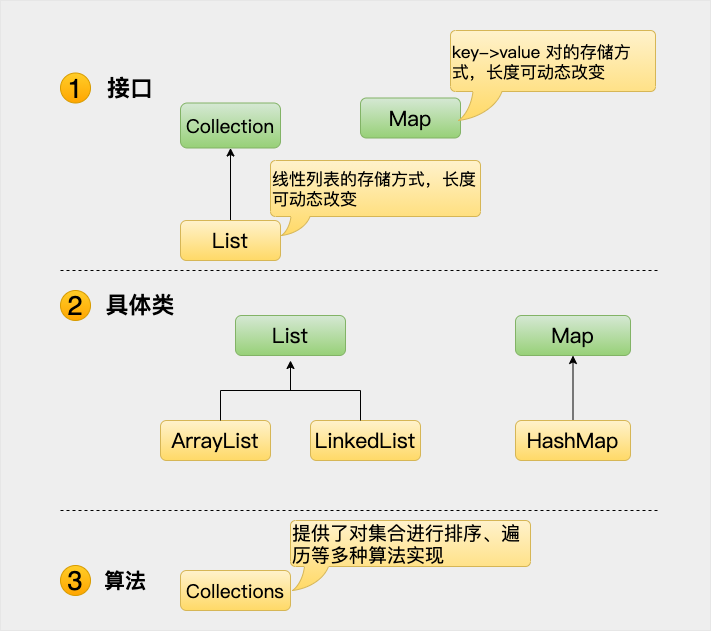
常见的集合接口:
- Collection 接口
- 存储一组不唯一、无序的对象
- Java 不提供直接继承自Collection的类,只提供继承于 Collection 的子接口(如List和set)
- List 接口
- 存储一组不唯一,有序的对象
- 动态增长,根据实际存储的数据的长度自动增长 List 的长度
- 查找元素效率高
- 插入删除效率低,因为会引起其他元素位置改变
- Set 接口
- 存储一组唯一,无序的对象
- 检索效率低下
- 删除和插入效率高,插入和删除不会引起元素位置改变
- Map 接口
- 存储一组键值对象,提供 key 到 value 的映射
常见的标准集合类:
-
ArrayList
-
该类实现了 List 的接口;
-
允许有 null 元素;
-
实现了长度可变的数组,在内存中分配连续的空间;
-
遍历元素和随机访问元素的效率比较高;
-
ArrayList 增长当前长度的 50%,插入删除效率低;
-
该类是非同步的,在多线程的情况下不要使用
-
-
LinkedList
- 该类实现了 List 接口;
- 允许有 null 元素;
- LinkedList 查找效率低;
- 采用链表存储方式,插入、删除元素时效率比较高;
- 该类没有同步方法
-
HashSet
-
该类实现了 Set 接口;
-
底层使用 HashMap 实现,查询效率较高;
-
由于采用 hashCode 算法直接确定元素的内存地址,增删效率也挺高的;
-
不允许出现重复元素;
-
不保证集合中元素的顺序;
-
允许包含值为 null 的元素,但最多只能一个
-
-
HashMap
- HashMap 是一个散列表,存储的内容是键值对(key-value)映射;
- 该类实现了 Map 接口,根据键的 hashCode 值存储数据,具有很快的访问速度;
- 最多允许一条记录的键为null,不支持线程同步
3. ArrayList 类
ArrayList 是可以动态增长和缩减的索引序列,它是基于数组实现的 List 类。该类封装了一个动态再分配的 Object[] 数组,每一个类对象都有一个 capacity 属性,表示它们所封装的 Object[] 数组的长度,当向 ArrayList 中添加元素时,该属性值会自动增加。
如果想 ArrayList 中添加大量元素,可使用
ensureCapacity方法一次性增加 capacity,可以减少增量重新分配的次数,提高性能。
ArrayList 的用法和 Vector 相类似,但是 Vector 是一个较老的集合,具有很多缺点,不建议使用。
另外,ArrayList和Vector的区别是:
- ArrayList 是线程不安全的,当多条线程访问同一个ArrayList集合时,程序需要手动保证该集合的同步性;
- Vector 则是线程安全的。
ArrayList 中的元素实际上是对象,如果我们要存储其他类型,而 <E> 只能为引用数据类型,这时我们就需要使用到基本类型的包装类。
3.1 ArrayList 的数据结构
-
ArrayList 是一种线性数据结构,它的底层是用数组实现的,相当于动态数组,其容量是动态调整的。
-
数组元素类型为 Object 类型,即可以存放所有类型数据。对 ArrayList 类的实例的所有的操作底层都是基于数组的。
3.2 ArrayList 源码分析
为什么要先继承 AbstractList,而让 AbstractList 先实现 List 接口?而不是让 ArrayList 直接实现 List 接口?
原因:接口中全都是抽象的方法,而抽象类中可以有抽象方法,还可以有具体的实现方法,正是利用了这一点,让 AbstractList 先实现接口中一些通用的方法,而具体的类通过继承(如 ArrayList 就继承这个 AbstractList 类)拿到一些通用的方法,然后自己再实现一些自己特有的方法,这样一来,让代码更简洁,减少重复代码。
ArrayList 实现的接口:
-
List 接口
-
RandomAccess 接口
一个标记性接口,它的作用就是用来快速随机存取。
- 如果实现了该接口,使用普通的 for 循环来遍历,性能更高,例如 ArrayList;
- 而没有实现该接口,使用 Iterator 来迭代,这样性能更高,例如 LinkedList。
-
Cloneable 接口
实现了该接口,就可以使用
Object.clone()方法 -
Serializable 接口
实现该序列化接口,表明该类可以被序列化
什么是序列化?简单的说,就是能够从类变成字节流传输,然后还能从字节流变成原来的类。
常用方法
boolean add(E e)- 在列表的末尾顺序添加元素(起始索引位置从 0 开始)void add(int index, E element)- 在指定的索引位置添加元素(索引位置必须介于 0 和列表中元素个数之间)void grow(int minCapacity)- 扩展数组大小(ArrayList 的核心方法)E get(int index)- 返回指定索引位置处的元素(取出的元素是 Object 类型,使用前需要进行强制类型转换)E set(int index, E element)- 修改 ArrayList 中的元素boolean remove(Object o)- 从列表中删除元素E remove(int index)- 从列表中删除指定位置元素(起始索引位置从0开始)int size()- 返回列表中的元素个数boolean contains(Object o)- 判断列表中是否存在指定元素(可能需要重写equals()方法)indexOf(Object o)- 从头开始查找与指定元素相等的元素(包括 null 元素)lastIndexOf(Object o)- 与indexOf()方法方向相反
更多方法内容详见:Java ArrayList
构造函数
public ArrayList(int initialCapacity)public ArrayList()public ArrayList(Collection<? extends E> c)
简单来说,
ArrayList的构造方法就是初始化一下储存数据的容器,即elementData元素
4. LinkedList 类
LinkedList 是非同步的。
4.1 LinkedList 的数据结构
- LinkedList 是一种可以在任何位置进行高效地插入和移除操作的有序序列,基于双向链表(不是双向循环列表)实现。
- LinkedList 是一个继承于 AbstractSequentialList 的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
4.2 LinkedList 源码分析
内部类 Node 是实现 LinkedList 的关键。
LinkedList 实现的接口:
-
List 接口
能对 LinkedList 进行队列操作
-
Deque 接口
能将 LinkedList 当作双端队列使用
-
Cloneable 接口
重写了函数
clone(),能实现克隆 -
Serializable 接口
意味着 LinkedList 支持序列化,能通过序列化去传输
构造函数
public LinkedList()public LinkedList(Collection<? extends E> c)
常用方法
-
boolean add(E e)- 向 LinkedList 中添加一个元素,并且添加到链表尾部 -
boolean add(Collection<? extends E> c)- 将一个集合的所有元素添加到链表后面 -
boolean add(int index, Collection<? extends E> c)- 将一个集合的所有元素添加到链表的指定位置后面 -
void addFirst(E e)- 在列表的首部添加元素 -
void addLast(E e)- 在列表的尾部添加元素 -
E get(int index)- 返回指定位置的元素 -
E getFirst()- 返回列表中的第一个元素 -
E getLast()- 返回列表中的最后一个元素 -
boolean remove(Object o)- 删除某一元素 -
E removeFirst()- 删除并返回列表中的第一个元素 -
E removeLast()- 删除并返回列表中的最后一个元素 -
int indexOf(Object o)- 查找指定元素从前往后第一次出现的索引
迭代器
- 内部类
ListItr - 内部类
DescendingIterator
5. Vector 和 Stack
5.1 Vector
- Vector 是一个可变化长度的数组
- Vector 是一个线程安全的类,如果使用需要线程安全就使用 Vector,如果不需要,就使用 ArrayList
- Vector 的继承关系和层次结构与 ArrayList 一模一样
- Vector 线程安全是因为它的方法都加了
synchronized关键字
在开发中,建议不用 Vector,如果需要线程安全的集合类直接用
java.util.concurrent包下的类。原因:Vector 在你不需要进行线程安全的时候,也会给你加锁,导致了额外开销。
5.1.1 Vector 源码分析
Vector 的本质是一个数组,特点能是能够自动扩增,扩增的方式跟 capacityIncrement 的值有关
属性
capacityIncrement小于或等于 0 时,扩展数组时每次扩展两倍,其余情况按属性实际大小进行
构造函数
public Vector(int initialCapacity, int capacityIncrement)public Vector(int initialCapacity)- 内部调用构造函数 1,并使形参 capacityIncrement 为 0public Vector()- 内部调用构造函数 2,并使形参 initialCapacity 为 10public Vector(Collection<? extends E> c)
核心方法
每个方法上比 ArrayList 多了一个
synchronized关键字,其他都一样。
5.2 Stack
Stack 为 Vector 子类
操作方法
E push(E item)- 把项压入堆栈顶部synchronized E pop()- 移除堆栈顶部的对象,并作为此函数的值返回该对象synchronized E peek()- 查看堆栈顶部的对象,但不从堆栈中移除它boolean empty()- 测试堆栈是否为空synchronized int search(Object o)- 返回对象在堆栈中的位置,以 1 为基数
Stack 类的方法是同步的,所以也是线程安全
6. List 总结
6.1 ArrayList 和 LinkedList 区别
- ArrayList 底层是用数组实现的顺序表,是随机存取类型,可自动扩增,并且在初始化时,数组的长度是0,只有在增加元素时,长度才会增加。默认是10,不能无限扩增,有上限,在查询操作的时候性能更好
- LinkedList 底层是用链表来实现的,是一个双向链表(注意这里不是双向循环链表),顺序存取类型。在源码中,似乎没有元素个数的限制,应该能无限增加下去,直到内存满了再进行删除,增加操作时性能更好。
两者都是线程不安全的,在 iterator 时,会发生 fail-fast
6.2 ArrayList 和 Vector 的区别
- ArrayList 线程不安全,在用 iterator 时会发生 fail-fast
- Vector 线程安全,因为在方法前加了
synchronized关键字,也会发生 fail-fast
7. fail-fast 和 fail-safe
7.1 fail-fast 和 fail-safe 什么情况下会发生
简单来说:在 java.util 下的集合都是发生 fail-fast,而在 java.util.concurrent 下的发生的都是fail-safe。
7.2 fail-fast 和 fail-safe 区别
-
fail-fast,快速失败
例如在 ArrayList 中使用迭代器遍历时,有另外的线程对 ArrayList 的存储数组进行了改变,比如 add、delete 等,使之发生了结构上的改变,所以 Iterator 就会快速报一个
java.util.ConcurrentModificationException异常(并发修改异常),这就是快速失败。 -
fail-safe,安全失败
在
java.util.concurrent下的类,都是线程安全的类。在迭代的过程中,如果有线程进行结构的改变,不会报异常,而是正常遍历,这就是安全失败。
-
为什么在
java.util.concurrent包下对集合有结构的改变,却不会报异常?在 concurrent 下的集合类增加元素的时候使用
Arrays.copyOf()来拷贝副本,在副本上增加元素,如果有其他线程在此改变了集合的结构,那也是在副本上的改变,而不是影响到原集合,迭代器还是照常遍历,遍历完之后,改变原引用指向副本,所以总的一句话,就是如果在此包下的类进行增加或删除操作,就会出现一个副本,所以能防止fail-fast。这种机制并不会出错,所以我们叫这种现象为fail-safe。 -
Vector 也是线程安全的,为什么是 fail-fast 呢?
并不是说线程安全的集合就不会报 fail-fast,而是报 fail-safe。
出现 fail-safe 是因为它们在实现增删的底层机制不一样,就像上面说的,会有一个副本,而像 ArrayList、LinkedList、Vector等,它们底层就是对着真正的引用进行操作,所以才会发生异常。
-
既然是线程安全的,为什么在迭代的时候,还会有别的线程来改变其集合的结构呢?
因为在迭代的时候,根本就没用到集合中的删除、增加、查询的操作,就拿 Vector 来说,我们都没有使用那些加锁的方法,即方法锁放在那没人拿,在迭代的过程中,有人拿了那把锁,我们也没有办法,因为那把锁就放在那边。
8. HashMap
HashMap 基于哈希表的 Map 接口实现,存储内容是键值对 <key,value> 映射。
HashMap 类不保证映射的顺序。
8.1 HashMap 数据结构
HashMap 在 JDK 1.8 前的数据结构为链表散列,在 JDK 1.8 后的数据结构为(数组+链表+红黑树)。
HashMap 类有两个属性影响性能:
- initialCapacity
initialCapacity 就是数组的长度,一个初始化容量仅仅是在哈希表被创建时的容量;initialCapacity 默认为 16
- loadFactor
loadFactor 是控制数组存放数据的疏密程度。
当 HashMap 条目数量超过了加载因子乘以当前的容量,那么哈希表将进行 rehash 操作(内部的数据结构会被重新建立),同时 HashMap 容量扩充至两倍;loadFactor 默认为 0.75
8.2 HashMap 源码分析
HashMap 实现的接口
-
Map<K,V> -
Cloneable能够使用
clone()方法;在HashMap中,实现的是浅层次拷贝,即对拷贝对象的改变会影响被拷贝的对象
-
Serializable能够使之序列化,即可以将HashMap对象保存至本地,之后可以恢复状态
HashMap 类属性
- 上述
initialCapacity、loadFactor TREEIFY_THRESHOLD- 链表转红黑树的阈值UNTREEIFY_THRESHOLD- 红黑树转链表的阈值threshold- 临界值,当实际大小(容量 * 填充因子)超过临界值时,会进行扩容MIN_TREEIFY_CAPACITY- 可以对容器进行树化的 HashMap 容量阈值- …
构造方法
构造方法中,并没有初始化数组的大小,数组在一开始就已经被创建了。
构造方法只做两件事情:
- 初始化 loadFactor
- 用 threshold 记录下数组初始化的大小
HashMap()HashMap(int initialCapacity)HashMap(int initialCapacity, float loadFactor)HashMap(Map<? extends K, ? extends V> m)
常用方法
V put(K key, V value)- 将键/值对添加到 HashMap 中V get(Object key)- 获取指定 key 对应的 value
8.3 HashMap 与 Hashtable 区别
-
HashMap:
- HashMap 不是线程安全的;
- HashMap 可以接受为 null 的键 (key) 和值 (value) ;
- HashMap 重新计算 hash 值
-
Hashtable:
- Hashtable 是一个散列表
- Hashtable 的函数都是同步的,这意味着它是线程安全的;
- Hashtable 的 key、value 都不可以为 null;
- Hashtable 直接使用对象的 hashCode
9. 迭代器
所有实现了 Collection 接口的容器类都有一个
iterator()方法,用以返回一个实现 Iterator 接口的对象。
Iterator 对象称作为迭代器,用以方便的对容器内元素的遍历操作,Iterator接口定义了如下方法:
boolean hashNext()- 判断集合是否还有元素Object next()- 获取集合中遍历的当前元素void remove()- 删除集合中的元素
10. 泛型
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
通配符:?
用法:
< ? >
11. Collections 工具类
Java 提供了一个操作 Set、List 和 Map 等集合的工具类:Collections,该工具类提供了大量方法对集合进行排序、查询和修改等操作,还提供了将集合对象置为不可变、对集合对象实现同步控制等方法。
Collections 类无需创建对象,完全由在 Collection 上进行操作或返回 Collection 的静态方法组成。
常用操作
-
排序操作
-
查找、替换操作
-
同步控制
Collections 类提供了多个
synchronizedXxx()方法,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。 -
设置不可变集合
-
…
